


Bring order to chaos: Setting up a production troubleshooting and remediation process for 🐛

[I love books, the physical kind. You can’t replicate the feeling of paper with a Kindle. So, I’m going to be taking the best of these newsletters, re-editing, and making a limit book run. Click here to learn more.]
Dealing with bugs, fixes, and patches is unavoidable for PMs working with software products at a startup. In the beginning, when there are few customers and features, it’s simple. Identify the issue, investigation, and a chat with an engineer to fix it. Maybe even the technical cofounder makes the code change. But as the number of customers grows and the codebase gets more complex, it’s easy for issue triage to consume all of a PM’s time. You now need to set up a production troubleshooting and remediation process. Let me show you.

What is a troubleshooting and remediation process?
It’s actually two processes, best run sequentially.
Troubleshooting is the process of identifying and restoring immediate functionality.
Remediation is the process of “making up” for users or customers impacted by the issue.
Here’s an analogy. You show up to the ER with a broken leg and you’re bleeding all over. Troubleshooting is the doctor figuring out why you’re at the ER, what’s causing the bleeding and stopping it so you don’t die. Yes, you want to walk again. Maybe physical therapy (i.e., remediation) is needed, but you won’t get there if you're dead.

The 5 components
It’s easy and you’ve likely practiced these but didn’t know the vocabulary.
Identification and logging: How was the issue brought to attention (e.g., Slack, email, Trello, Jira, Linear, phone call)? What information about the issue is available (e.g., logs, screenshots, screen captures, steps to reproduce)
Communication: How are you going to communicate about the issue. Who do we need to inform, who needs to do what, who should we consult, and who will make key decisions?
Prioritization: Should we work on a reported issue? How will we decide which issue to work on if there are simultaneous issues?
Escalation: How do we handle disagreements (e.g., we can’t resolve among ourselves, what do we do?)
Closure: Do we celebrate? Should we investigate beyond? Do we need to perform a root cause analysis or a review?

Steps for Creating A Good Troubleshooting Process
Gather 3 -5 people and bring them along. You’re introducing a new process, best to co-opt people into its creation. Pick people who are currently involved when dealing with bugs (e.g., sales, customer success, engineering, finance, even the CEO). Your goal is to create, document, and communicate the new troubleshooting process collaboratively. See SPADE decision-making process for more detail on how to execute.
Create and use a reporting template. As issues increase, you can’t scale if is “yelling the loudest gets attention”. While people commonly complain about filling out issue forms because it’s long and tedious, it doesn’t have to be. Here’s a simple 5 question template that you can use in any tool, whether Git, Jira, Trello, Asana, or Slack. The goal is to reduce 15 minutes of conversations where you’re a chatbot.
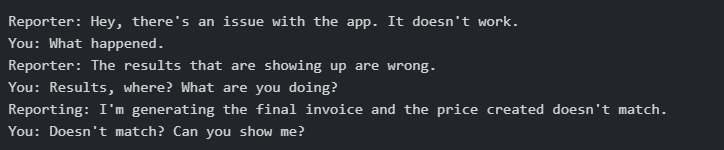
Define priority and escalation process.

First, the reporter MUST pick a priority when reporting an issue (see above). It’s the same reason why people decide for themselves whether to visit the ER or go to Walgreens. I can’t stress this enough. Some reporters will feel very uncomfortable making this decision because they are unfamiliar (“Wait, I get to tell you to drop everything?”). You can help by asking, “What type of response do you want from me?”
Once the reporter assigns a priority, it’s up to the PM (assuming the issue is sent to the PM) to determine if she or he agrees (e.g., just because you show up at the ER doesn’t mean a doctor thinks your issue is life or death. But a doctor is going to go through the process to check.).
If you agree with the reporter, move on. If you disagree, inform the reporter and downgrade (or upgrade). This is where the escalation process is needed to resolve disagreements. You need to define who has final authority (e.g. PM has final authority, issues go up reporting hierarchy and VP of Sales has final authority, reporters are always right, rock-paper-scissors). No perfect answer, but everyone needs to understand how to resolve disagreements otherwise, you’ll have too many variations and lots of wasted time.Define how to communicate updates. Many issues won’t be solved instantly. So, you’ll need to give updates. Easy when it’s five people, hard when it’s 50 people who all need different information to do their jobs.
Pick a channel for communication and stick to it. I recommend email via group email distribution. Create a group (e.g., Google groups) and allow people to auto subscribe. This way, you can easily add and people can remove themselves. This becomes the form you’ll use to communicate updates. Make this a broadcast, not an email chain. Use an eye catching subject line (e.g., “PRIORITY 0 ISSUE UPDATE: WEBISTE IS DOWN”) Keep your emails short with links to Notion or other documents for people who want more details.
For Priority 0 and 1 issues, provide updates even if the update is “nothing to update”. When shit hits the fan, people from all over the company will reach out to you for information. However, sometimes, you literally have no further information to give: “We’re still working on it.” If that’s the case, provide an update stating so with a time for the next update (e.g., “Nothing to update. Still investigating. Next update in 30 minutes”). This will free up your time to work on resolving the issue.
Define priority 2 and 3 issues as no direct communication. By default, these are issues that aren’t so urgent, you need to drop what you’re doing. So, set the standard ahead of time that you won’t be providing updates. It’ll get hammer through your normal process of figuring out what to do next sprint.
Have closure and rest. After telling everyone it’s all resolved, we forget the stress induced for handling priority 0/1 issues. People may be templated to jump right back into what they were previously working on, but I’ve learned from my own mistakes, it’s better to celebrate as a team and take a 10 minute mental break. Yahhhh! Prior to remote work, maybe it’s grab a drink or coffee. Now, maybe share some tunes or hang out. What ever you decide, but make it a fun habit.
Set a time in the future to review the process. People are going to complain about the “new” troubleshooting process. It won’t be perfect and as a way to help people adapt, set a time for people to review (i.e., literally schedule something on people’s calendars 2 months ahead). You’ll want to wait 2 - 4 cycles so people will get a chance to try the process end-to-end. And when people complain, that’s okay. Invite them to the meeting in the future for them to vent.




What about the remediation process?
Having “stopped the bleeding”, it’s now time to rebuild. Sometimes, it’s as easy as asking the customer to “retry”. Other times, there’s more work that needs to be done, typically to fix under data issues. Perhaps a record was deleted and needs to be restored. Maybe some messages were stuck or a customer has to be refunded. Regardless, more work needs to be done.
Handling remediation should follow the same process for troubleshooting issue (i.e., use the template, log it, set a priority, determine if there’s agreement, escalate if needed). The difference here is you, the PM, assigns a starting priority. Then, you’ll want to confirm that priority with typically sales, customer success, or customer support.
Here, it’s important not to combine troubleshooting with remediation. That’s because there maybe not ways to “compensate” injured customers without engineering work. Talk to sales or customer success. While painful, it’s sometimes easier and faster to ask the customer to start over because the effort to remediation may be more time consumer.
Other Lessons Learned The Hard Way
Don’t blindly try to perform root cause analysis. Shit’s going to break. Processes that you designed aren’t going to work. Customers will be upset and so will your coworkers. Someone is going to suggest after an issue to conduct a root cause analysis under the good mantra: “We learn from our mistakes so we don’t repeat them.” Don’t fall into the trap! Here’s why:
a) You don’t have the time nor the information to conduct proper root cause analysis.
b) In an early stage, <100 people companies, your tech stack, people and process will change and some issues will no longer be applicable 5 months later. Change should be fast, so this is a waste of time.
c) Making fundamental changes is difficult (e.g., Sara worked too many hours and we didn’t have a backup infrastructure engineer. In a hurry, she made a production deploy with the wrong command. If only we didn’t work so many hours or so hard).
Instead, suggest some band-aids that’s easy to implement. People are solution oriented and probably have them top of mind. Pick 1 or 2 at most and make a change.
Offer 1:1 guidance when someone is filling out the template the first time. Next time someone pings you about an issue without submitting a template, say, “Hey, you got 15 minutes to fill out the reporting template? I can jump on the video right now and guide you.” Spend quality time answering questions. Don’t become the scribe, but give encouragement. After 15 minutes, then take over by updating the document once the reporter has tried filling it out.
Introduce technology so reporters don’t have to type. With tools like Loom, Jing, CamStudios, (plus features built-in to Mac and Windows for screen and video capture), reporters don’t have to be typing everything. They could be sharing a recording of the issue.
Don’t use a risk matrix (i.e., priority vs severity). If you Google, you’ll discover the priority versus severity matrix.

It’s a neat intellectual framework, but terrible in practice. From my experience, there is too much variability in how people define along two axis. But don’t just take my word for it.
Risk matrices do not necessarily support good (e.g., better-than-random) risk management decisions and effective allocations of limited management attention and resources.
… the common assumption that risk matrices, although imprecise, do some good in helping to focus attention on the most serious problems and in screening out less serious problems is not necessarily justified.
[For severity] Users with different risk attitudes might have opposite orderings … As a result there is no objective way to classify the relative severities of such prospects with uncertain consequences.
In short, you’re already dealing with people who view priorities differently (e.g., I might go to Walgreens and self medicate while you’ll visit the ER for the same issue). When you add severity as the second axis, it gets even more confusing. As a result, stick with just priority.
Timebox priority 1 issues to 15-30 min max to make a decision to downgrade or upgrade. When you only use the priority ordinal ranking, you’ll end up with most reporters suggesting a 1, which may then get downgraded into a 2 if there’s already some reasonable workaround. That’s normal and the way to perform this is to define ahead number of priority 1 issues you’ll handle per week. If you start collecting more priority issues than you can resolve, it means you need to dedicate more resources on delivery quality rather than new development.
Handle bugs versus issues differently, but allow reporting to be the same. Reporters don’t care if the issue is a bug (i.e., a bug is something that deviates from expected behavior) or masked as a feature request. However, it’s important for you to know how to separate the two. That’s because bugs are “easier” to solve because you have a defined expected behavior. This is something software engineering can fix because there’s a clearly defined outcome that’s currently broken. However, issues masked as features requests can’t be solved so quickly because you have to validate and define the new expected behavior.

Interesting additional reads:
Thank you for writing this! I read a number of PM blogs and this probably the most practical piece of advice I've seen in 2021. I am currently serving as the Head of Product, Engineering Manager, and sole QA-tester so I will never tire of practical suggestions.
I do all of this except for having the reporter pick a priority upon submission. Across my 10 years as a PM, I've always worked at companies where "ONLY PMS CAN TOUCH THE PRIORITY FIELD!!!" Asking the reporter to think about, and articulate a priority is so clever as a conversation starter! I'm eager to introduce that step to my company and see where it takes us.
I look forward to reading through your other posts as well as future ones!